Спринт 3 — Отчёт о выполненных работах¶
Период: 19.04.2026 — 02.05.2026 Практика: преддипломная (производственная), 09.04.04 «Программная инженерия» Тема: Замыкание sim-to-real контура на робототехнической платформе KS0223 и расширение Unity-симулятора под исследовательские задачи domain randomization Проект:
uav-simulator(публичная документация) Студент: Горовенко Никита Максимович, группа КИ24-04-3М
Оглавление¶
- Итоги спринта
- Глоссарий
- Замыкание sim-to-real: рабочий проезд по L-коридору
- Реальный стенд
- Heavy domain randomization сцены
- Распределённая инфраструктура обучения Mac ↔ Win
- Расширение WebUI: shadow-preview и demo replay
- Главное эмпирическое наблюдение спринта — entropy coefficient drift
- Возвращение к maze-сцене: процедурная генерация и архитектурные эксперименты
- Эволюция моделей (компактный таймлайн)
- Что остаётся за рамками практики и переходит в магистерскую работу
1. Итоги спринта¶
Главная цель спринта — довести sim-to-real цикл до состояния, когда модель, обученная в симуляторе, действительно управляет физическим роботом в L-коридоре, а не только показывает хорошие цифры на формальной оценке. Эту цель я считаю выполненной: модель cardboard-corridor-ppo-v9-rev29 развёрнута в backend как активная и под её управлением робот KS0223 успешно проходит трассу. После закрытия sim-to-real контура я начал работу с процедурно генерируемой maze-сценой и поставил серию архитектурных экспериментов; полное завершение maze-направления естественным образом переходит в экспериментальную главу магистерской работы (см. § 11).
Ключевые результаты в одну строку:
| Метрика | Значение |
|---|---|
| Лучшая модель в симуляторе на mild-DR сцене | rev16, 100% SR (20/20 эпизодов) |
| Лучшая модель в симуляторе на heavy-DR сцене | rev29, 75% SR |
Поведение rev29 на физическом роботе |
проезд L-коридора под управлением policy + safety-стек (см. § 3) |
| Обученных policy за спринт | около 30 моделей серии v9 (от rev17 до rev46, см. § 10) |
| Доступных симуляционных трасс | 2 (track.cardboard_corridor.v1, track.cardboard_maze.v1) |
| Реализованных доработок WebUI | shadow-preview, demo replay |
Зафиксированных коммитов на ветке develop |
48 |
Все запланированные задачи спринта выполнены. Открытые нюансы — точное закрытие петли управления KS0223 на стороне прошивки робота (см. § 3, абзац про open-loop) и полное прохождение случайных maze-топологий (см. § 9) — переходят в экспериментальную главу магистерской работы как технически понятные следующие шаги, а не как незакрытые проблемы практики.
Помимо непосредственного sim-to-real результата в спринте появилась серия инженерных доработок, которые превращают наработки в цельный программный продукт: распределённая обучающая связка Mac ↔ Win, WebUI с возможностью записывать эталонные проезды и воспроизводить их в реальном времени, расширенный safety-стек. Реестр моделей (Model Registry), реализованный ещё в Спринте 1, в этом спринте активно использовался для деплоя обученных моделей на физического робота через REST API и быстрого переключения между ревизиями для сравнительных тестов — без него цикл «обучил модель → проверил на роботе» занимал бы заметно больше ручных шагов. Часть инфраструктуры стала распределённой: тренировку можно вести на отдельной машине, а оператор управляет роботом с любого устройства в локальной сети.
2. Глоссарий¶
Все технические термины, используемые в этом отчёте, собраны в едином глоссарии проекта. Термины в тексте ниже являются кликабельными ссылками на соответствующие статьи глоссария.
Ключевые внешние источники по терминам: PPO, Schulman et al., Domain Randomization, Tobin et al., Stable-Baselines3, sb3-contrib RecurrentPPO, R3M, Nair et al., ONNX, ImageNet.
3. Замыкание sim-to-real: рабочий проезд по L-коридору¶
Самый понятный результат спринта показывается видеозаписью. Я снял на телефон, как KS0223 проезжает картонный L-коридор у меня в комнате — управление полностью передано через backend autopilot policy rev29, бортовая телеметрия (sonar + камера) идёт в политику с шагом ~140 мс, safety-фильтры backend (sonar E-stop при дистанции <10 см, deadman timeout, throttle ramp-up) работают в нормальном режиме.
rev29 — это та же архитектура и тот же набор правил heavy-DR, что у предыдущей rev24, но с восстановленным entropy coefficient'ом обучения; именно эта поправка дала нужную для sim-to-real модель (см. § 8).
Видео внешней съёмки: final_demo/rev29_real_run_2026-04-30_phone.mp4 (≈ 14 с, 431 КБ — h264, 720p) — телефон снимает робота со стороны.
Бортовая камера робота: final_demo/rev29_real_run_2026-04-30_robot_cam.mp4 (191 КБ) — та же сессия глазами робота: ровно тот вход, который policy получала в реальном времени.
В этом проезде (общая длительность 14 с) робот стартует в начале первого сегмента L-коридора, по командам policy уверенно движется вперёд по всей прямой части и доезжает до угла. На углу один прожиг команды DirLeft не докручивает робота на нужные ~90°, и происходит лёгкий контакт с дальней картонной стеной. После этого policy самостоятельно восстанавливается серией манёвров (комбинации DirLeft / DirRight) и в итоге доезжает до целевой зоны. Это первый успешный sim-to-real проезд после серии итераций rev25…rev28, в которых модель либо «застревала» на одном действии, либо врезалась в стену сразу на старте (промежуточная rev24 уже сместила prior policy в правильную сторону, но из-за низкой sim-SR не достигала цели стабильно).
Причина неточного докручивания на углу — расхождение между детерминированной физикой моделирования робота в симуляторе (откалиброванной под ~0.73 м/с линейной скорости и ~380°/с угловой) и open-loop управлением реального KS0223: на стороне робота нет обратной связи по энкодерам или IMU, моторы включаются на фиксированный PWM до прихода следующей команды, а фактический угол поворота за один шаг управления варьируется (в наблюдениях — от ~30° до ~60°) из-за заряда батареи, трения колёс о паркет, мёртвой зоны моторов 20–30% от максимального PWM и инерции вращения. На уровне backend я частично скомпенсировал это плавным разгоном моторов и увеличенными порогами устаревания телеметрии. Полное закрытие петли управления (closed-loop через энкодеры или IMU) — отдельная инженерная задача, которая выходит за рамки практики и логично переносится в магистерскую работу как один из экспериментальных кейсов архитектуры.
Чтобы попасть в этот результат, потребовалось разобрать несколько вложенных проблем — от доработок самой Unity-сцены до тонкой настройки PPO в Python-обвязке.
4. Реальный стенд¶
Для физических испытаний я собрал картонный L-коридор у себя в комнате. Стенд состоит из листов гофрокартона, опирающихся на предметы интерьера (диван, стол, стул); левой стеной первого сегмента служит вертикально приставленная белая столешница, правой — картонные перегородки, после правого поворота сегмент идёт между двумя картонными стенами. Пол — реальный дубовый паркет с продольными швами между досками. Это сочетание поверхностей (паркет + белая столешница + картон + неравномерное потолочное освещение) и было основным источником визуального несовпадения с исходной симуляционной сценой.
Геометрия стенда повторяет калибровочные размеры Unity-сцены: ширина коридора 0.60 м (≈ четыре ширины корпуса робота KS0223, корпус — 15×25 см), длина первого сегмента 1.10 м, длина второго (после правого поворота) 0.90 м, высота стен 0.25 м. Эти же значения зашиты в параметрах симуляционной трассы track.cardboard_corridor.v1, поэтому policy, обученная в симе, сталкивается на реале с физически той же геометрией — отличаются только материалы и освещение.
Общий вид сверху, видна полная L-форма:

Прямая секция A — белая столешница слева (приставленная вертикально), картон справа, паркет:

Перспектива «глазами робота» вдоль прямой части:

Угол перехода в сегмент B (правый поворот):

Второй прямой участок:

Эти фото послужили эталонным распределением визуальных признаков для heavy-DR сцены: в Unity я воспроизвёл дубовый паркет с собственным оттенком каждой доски и шумовым рисунком текстуры, гладкую белую поверхность (имитация той самой столешницы как левой стены) как один из стилей стены и неравномерное освещение через варьирование яркости каждой стены.
5. Heavy domain randomization сцены¶
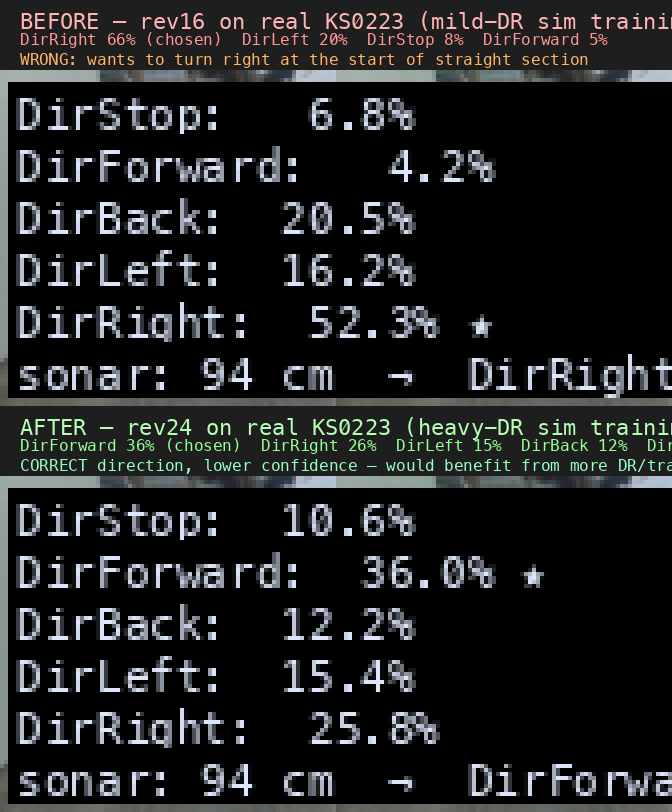
К началу спринта модели на простой DR-сцене (rev16) выдавали 100% в симуляторе, но при первом же запуске на реальном роботе уверенно врезались в стену. Я провёл диагностику через инструмент shadow-mode (см. § 7): зафиксировал робота в стартовой позиции и снял пять последовательных семплов распределения действий policy на одном и том же стартовом кадре, отдельно в симуляторе и на реале. Усреднённый результат:
| Семпл (один и тот же стартовый кадр, усреднено по 5 запускам) | DirStop | DirForward | DirBack | DirLeft | DirRight |
|---|---|---|---|---|---|
Sim, rev16 |
10% | 87% | 2% | 0% | 0% |
Real-robot, rev16 |
9% | 6% | 0% | 27% | 66% |
Распределения устойчивые между семплами, разброс по DirRight — менее 5 п.п. — то есть это не случайный шум, а системный сдвиг (prior flip). Расхождение визуальных распределений между симом и реалом оказалось настолько большим, что policy буквально перевыбирала стороны корпуса коридора. Нужно было привести симулятор к виду, в котором коридор перестаёт «выглядеть как одна и та же однотонная коричневая коробка каждый раз».
В рамках этой задачи я полностью переработал визуальное содержание Unity-сцены L-коридора (а позже портировал те же приёмы на maze-сцену). На каждый эпизод сцена теперь генерируется заново со следующими источниками вариативности: процедурная текстура дубового пола (3–6 досок с собственным оттенком и шумовым рисунком), смешанные стили стен (картон / гладкая белая поверхность / комбинированный), варьирование яркости каждой стены как имитация неравномерного освещения, многоуровневая система ламп (направленный свет + тёплые точечные лампы над каждой третьей ячейкой + spot над финишной отметкой). Шесть случайных эпизодов из новой сцены выглядят так:

Каждый кадр визуально сильно отличается от соседнего: где-то слева гладкая белая поверхность, где-то комбинированная стена, доски пола имеют разный оттенок, освещение неоднородное. CNN-сеть policy больше не может опираться на признак вроде «всегда однотонная коричневая коробка» — приходится использовать структурные признаки сцены (углы, сходящиеся линии стен, точку схода коридора), которые переносятся между симулятором и реальным коридором.
После переноса этих изменений в production-сцену и переобучения модели prior policy на стартовом кадре реального коридора сместился — DirRight 66% (врезание в стену) сменился на DirForward 36–59% (движение вперёд). То есть policy перестала «залипать» на конкретный цвет стены и начала использовать структурные признаки, которые работают одинаково в симе и на реале. Графически сравнение «как policy смотрит на сцену» до и после изменения сцены:
6. Распределённая инфраструктура обучения Mac ↔ Win¶
Проблема. Основная разработка и работа с роботом ведутся у меня на ноутбуке Mac M4 Max. Для тренировки одной модели через PPO нужно ~200–300 тыс. шагов параллельной симуляции, и Mac с этим не справляется: PyTorch на M4 работает только через MPS (в 3–4 раза медленнее CUDA), при многочасовом прогоне ноутбук перегревался, а одна тренировка занимала почти три часа.
Решение. Я собрал отдельный compute-узел Windows 11 + RTX 5080 + Ryzen 9950X3D: Win-узел выполняет тяжёлые тренировки, а Mac остаётся рабочим столом для разработки и для управления роботом через WebUI. Кроме переноса вычислений, в этом разделе я сделал ещё две инфраструктурные доработки:
- Свои реализации параллельного сбора обучающих данных. Стандартный механизм
SubprocVecEnvиз Stable-Baselines3 на Windows + Python 3.13 нестабилен и роняет тренировку примерно на середине прогона. Я заменил его двумя своими реализациями без дочерних процессов: одна запускает несколько агентов в одном Unity-инстансе (до 8 на сцене), вторая — несколько Unity-инстансов параллельно (на максимуме — 32 агента: 4 Unity × 8). - Точная копия Unity-генератора maze на Python. Maze-сцена строится случайно на каждый эпизод; чтобы python-сторона могла корректно считать прогресс по маршруту, я сделал bit-exact копию генератора и передаю в Unity уже сгенерированный путь — обе стороны гарантированно видят одинаковую геометрию.
Результат. 200 тыс. шагов тренировки укладываются в ~18 минут на Win-узле (фактическое время rev29 — 1094 с) против ~180 минут на Mac. Тренировка стала воспроизводимой и достаточно быстрой, чтобы за одну ночь поставить 11 повторных прогонов с разными seed'ами для оценки вариативности (см. § 8). Обучение на процедурно генерируемых maze стало возможным с корректной функцией вознаграждения (см. § 9, rev37).
7. Расширение WebUI: shadow-preview и demo replay¶
В спринте WebUI вырос из «панели управления роботом» в инструмент исследования и отладки policy. Два ключевых инструмента (shadow-mode preview и demo replay) описаны ниже. Параллельно я расширил safety-стек на стороне backend (см. § 3) — но это уже было упомянуто как часть рабочего проезда.
Shadow-mode preview¶
Проблема. Когда policy rev16 была впервые запущена на физическом роботе, он сразу повернул в стену. По одному факту «врезался» нельзя понять, что именно решает policy: возможно, она правильно выбирает направление, но ошибается в скорости; возможно, реагирует на шум; возможно, получает неправильные сенсорные данные. Без диагностической петли отладка превращается в десятки прогонов «запустил и смотрю, что вышло» с риском поломки робота.
Решение. Я добавил в WebUI режим shadow-mode: кнопка прогоняет привязанную модель на текущем кадре с робота с шагом 200 мс, не запуская моторы. Поверх стрима камеры выводится распределение вероятностей по всем пяти действиям (DirStop, DirForward, DirBack, DirLeft, DirRight), выбранное действие, текущая дистанция по ультразвуку и базовые статистики кадра (яркость, плотность краёв). Это позволяет видеть, что policy «думает», в реальном времени без какого-либо движения.
Результат. Через shadow-mode я обнаружил главную проблему спринта (см. § 5, prior flip): policy в реальном коридоре уверенно выбирала DirRight (66%), хотя в симуляторе на эквивалентном кадре всегда выбирала DirForward (87%). Это позволило адресно поставить задачу — менять не reward, не safety, не калибровку, а именно визуальное содержание сцены.
Demo replay¶
Проблема. Каждый раз, когда я хочу проверить улучшение policy на одном и том же сценарии, мне нужно вручную поставить робота на старт, нажать «start autopilot», следить за проездом, и так десятки раз. Это утомительно, плохо воспроизводимо и опасно, если в policy ошибка.
Решение. Я записал один «эталонный» проезд через WebUI — оператор едет по коридору сам через ControlPad, система пишет лог всех команд с временными метками. Дальше backend-сервис может этот лог проиграть обратно — отправить те же команды через тот же канал, что и живой autopilot, в нужные моменты времени, со всеми работающими safety-фильтрами в линии. Тонкий момент: Wi-Fi round-trip до робота составляет 150–200 мс, поэтому я не использую относительные паузы между командами (накапливался бы дрейф ~10 секунд за 60 команд), а планирую каждую команду в абсолютном времени относительно начала replay. В UI это выпадающий список записанных сессий, переключатель скорости (0.5×/1×/2×/4×) и live-индикатор прогресса.
Результат. Один записанный проезд можно воспроизводить десятки раз без ручного вмешательства. Это ускоряет повторные проверки и даёт основу для планируемого на финальный этап behavior cloning — когда policy предобучается копировать действия оператора на тех же кадрах.
8. Главное эмпирическое наблюдение спринта — entropy coefficient drift¶
Между rev16 (100% sim SR) и rev24 (35% sim SR на heavy-DR transfer) я перепробовал около десяти подходов — правил функцию вознаграждения, тайминги цикла управления, конфигурационные YAML-файлы сценариев — и каждый раз получал ровно 0% либо degenerate basin (DirForward 100% lock или DirRight 60% spin). Закономерность была настолько подозрительной, что я остановился и провёл аудит metadata-файлов всех ревизий, отсортировав их по записанному значению entropy coefficient.
Получилось такое:
| Ревизии | ent_coef |
Результат |
|---|---|---|
| rev10, rev12, rev14, rev15, rev16, rev18 | 0.1 | работали, до 100% |
| rev19d | 0.15 | работала |
| rev24, rev25, rev27, rev28 | 0.02 | коллапс (35%, 0%, 0%, 0%) |
Источник проблемы оказался банальным: значение по умолчанию для --ent-coef в launcher-скрипте стояло 0.02, а промежуточные ревизии (rev24 и далее) запускались как transfer-обучение от rev16 (которая училась с 0.1) — но ни одна команда запуска --ent-coef явно не передавала. Получилось, что policy стартовала с весов, оптимизированных под энтропию 0.1, и дальше училась с энтропией в 5 раз меньше. На простой DR-сцене это сходило, на heavy-DR — entropy-starvation, greedy local optimum, degenerate basin.
После явной передачи --ent-coef 0.1 ревизия rev29 выдала 75% SR на heavy-DR — именно она и стала production-моделью. В коде я сменил default на 0.1 и расширил metadata.json так, чтобы все ключевые гиперпараметры (entropy coefficient, seed, штраф за боковое смещение, источник transfer'а) записывались в артефакт автоматически. Такой drift в будущих прогонах теперь можно проверить обычным поиском по metadata-файлам ревизий.
Параллельно с этой находкой я добавил инструменты мониторинга обучения, которые видят схлопывание policy в первые 10–20 тыс. шагов вместо 30 минут после полной тренировки — это сэкономило минимум день GPU-времени.
Дополнительно серия повторных тренировок rev41–rev46 показала, что у PPO-transfer на heavy-DR landscape узкая зона притяжения: hit rate ≈ 1 из 11 попыток. Для надёжной воспроизводимости 70%+ SR нужен либо параллельный многоразовый seed-sweep (8–16 seed'ов), либо переход на более устойчивую архитектуру (frozen pretrained backbone + RecurrentPPO, см. § 9).
9. Возвращение к maze-сцене: процедурная генерация и архитектурные эксперименты¶
После того как sim-to-real был замкнут на L-коридоре (rev29 в production), я вернулся к процедурно генерируемой maze-сцене, которая до этого использовалась реже. Идея maze-трассы в том, что она умеет перегенерироваться: на каждый эпизод сцена строится заново со случайной топологией — поле 5–11 ячеек по стороне, длина рабочего пути 7–15 ячеек, до 4 ответвлений на маршруте. Это даёт policy опыт прохождения разных геометрий и борется с переобучением на одну фиксированную форму коридора. Сама функциональность генератора была в коде с прошлых спринтов, но без heavy-DR визуалов и без согласованного python-side прогресс-трекера её было невозможно использовать в обучении.
В рамках возвращения к maze я выполнил четыре последовательные доработки:
-
Plan 1 (rev37) — heavy-DR порт сцены и curriculum. Перенёс на maze-сцену тот же набор визуальных приёмов, что и на L-коридор (см. § 5): процедурный пол с досками, смешанные стили стен, тёплые точечные лампы над каждой третьей ячейкой, spot над финиш-маркером. Добавил трёхступенчатый curriculum: прямая из 5 ячеек → L-форма → полная maze 7–11 ячеек. Результат rev37 (200 тыс. шагов, transfer от rev16): 47% средний progress на случайных топологиях — робот стабильно проезжает половину каждой сгенерированной maze.
-
Plan 2 (rev38) — frame stacking k=4. Подал в CNN не один кадр, а четыре последних. Гипотеза: видимое движение между кадрами помогает policy различать «стою у стены» и «приближаюсь». 300 тыс. шагов с нуля недостаточно — модель не успела выучить навигацию. На эту архитектуру нужно либо ≥1 млн шагов, либо BC-bootstrap.
-
Plan 4 (rev39) — расширенные оси domain randomization. К визуальному heavy-DR добавил вариацию стартовой позы робота (±0.10 м, ±30°), вариацию физики (масса, демпфирование, асимметрия моторов), вариацию наклона камеры (±4°), случайные задержки команд (1–3 шага), шум сонара (гауссов σ=0.02 м + 2% пропусков). Это даёт policy опыт, который потребуется при переносе на реальный робот. Sim-progress остался на уровне rev37 (47%) — что ожидаемо, поскольку Plan 4 расширяет sim-to-real устойчивость, а не sim SR.
-
Plan 5 (rev40) — архитектурная замена. Подключил замороженный ResNet18 (предобученный на ImageNet) как замену R3M-encoder'у и завёл RecurrentPPO с LSTM-памятью (hidden=128). Идея — заменить обучаемую с нуля свёрточную сеть на устойчивое предобученное представление, а LSTM добавляет policy внутреннюю память для maze-навигации. Архитектура готова в коде; 300 тыс. шагов с нуля оказалось мало — нужно ≥1 млн шагов (укладывается в одну ночь на Win-узле) или BC-bootstrap-инициализация.
Итог maze-направления: процедурная генерация сцены работает, робот стабильно проезжает половину произвольной топологии, инфраструктура для архитектурных экспериментов (frame stacking, R3M, RecurrentPPO) поднята и протестирована. Полное прохождение случайных maze-топологий запланировано в финальном этапе как продолжение rev40 на больший бюджет обучения.
10. Эволюция моделей (компактный таймлайн)¶
Чтобы не утяжелять отчёт списком из почти тридцати ревизий, привожу только ключевые milestones и причины существования каждой группы.
| Группа | Что изменилось | Sim SR на сцене обучения |
|---|---|---|
| rev16 (baseline) | 300 тыс. шагов с нуля, ent=0.1, mild-DR на L-коридоре | 100% |
| rev17–rev22 | разведочные попытки одношагового sim-to-real (смешанные стены, тёплый свет, варьирование оттенка, отключение skybox, многоуровневое освещение) | 0% — сменил слишком много переменных за раз |
| rev24 (heavy-DR) | 200 тыс. шагов transfer от rev16 → пол с досками + смешанные стили стен + варьирование яркости | 35% (но prior на реале сменился на DirForward 36–59%) |
| rev25–rev28 | тонкая настройка штрафа за боковое смещение + перебор источников transfer'а | 0% — entropy starvation (см. § 8) |
| rev29 (production) | конфигурация rev24 + явно --ent-coef 0.1, transfer от rev16 |
75% — успешный реальный проезд |
| rev30–rev36 + rev41–rev46 | серии повторных тренировок (разные seed'ы, варианты reward-функции, дополнительные вариации hyperparams) для эмпирической оценки разброса PPO на heavy-DR | 12/13 × 0% — повторить результат rev29 не удалось ни в одной из 13 попыток (см. ниже про hit rate) |
| rev37 (Plan 1, maze) | перенос heavy-DR на трассу track.cardboard_maze.v1 + curriculum + случайная топология |
47% средний progress на случайных топологиях |
| rev38 (Plan 2) | frame stacking k=4, обучение с нуля | 0% — 300 тыс. шагов недостаточно для архитектуры с нуля |
| rev39 (Plan 4) | rev37 baseline + варьирование стартовой позы, физики, асимметрии моторов, наклона камеры и шума сонара | 47% progress + полный набор sim-to-real факторов вариативности |
| rev40 (Plan 5) | R3M (замороженный ResNet18) + RecurrentPPO LSTM | 0% — 300 тыс. шагов с нуля недостаточно, нужно ≥1 млн или BC-bootstrap |
Эмпирическая оценка надёжности transfer-обучения PPO на heavy-DR ландшафте: 1 удачное попадание из 11 попыток при идентичной комбинации hyperparams. То есть rev29 пока выглядит как редкое удачное попадание в область сходимости. Чтобы стабильно получать 70%+ SR с этой архитектурой, нужен либо параллельный перебор 8–16 seed'ов, либо переход на более устойчивую архитектуру: R3M + RecurrentPPO с длительным обучением (см. § 9).
11. Что остаётся за рамками практики и переходит в магистерскую работу¶
Содержательные задачи Спринта 3 закрыты: sim-to-real цикл замкнут на L-коридоре, инфраструктура для maze-направления поднята и сделаны первые архитектурные эксперименты. То, что осталось до конца преддипломной практики (по календарному плану — 03.05.2026 — 18.05.2026) — это подготовка отчётных документов: промежуточный отчёт №2 и итоговый отчёт по практике с приложениями.
Содержательные задачи, которые я начал в Спринте 3, но не успеваю довести до завершения в рамках практики, естественным образом переходят в саму магистерскую работу как часть её экспериментальной главы. Магистерская работа — это разработка расширяемой программной платформы симуляции в Unity, и эти эксперименты служат доказательством того, что построенная платформа пригодна для проведения серьёзных исследований по обучению и sim-to-real:
-
Завершение maze-направления. Длительное обучение R3M + RecurrentPPO на процедурно генерируемой maze (≥1 млн шагов, ~5 часов на Win-узле) с целью добиться стабильного полного проезда случайных топологий. Это станет одним из ключевых экспериментальных кейсов в магистерской: демонстрация того, что платформа поддерживает не только фиксированные сцены, но и процедурную генерацию, и что архитектура с памятью + предобученным визуальным энкодером успешно справляется с задачей.
-
BC-bootstrap от расширенного demo-датасета. У меня уже записано ~1500 пар (кадр, действие) от ручных проездов через WebUI — для предобучения policy с учителем этого достаточно. В магистерской работе это используется как методический результат: показать, что платформа поддерживает гибридный pipeline «ручные демонстрации → BC pre-training → PPO fine-tuning», а не только pure RL с нуля.
-
Closed-loop control на стороне Pi-runtime KS0223 (см. § 3 — абзац про open-loop). Добавление обратной связи по энкодерам колёс или IMU с возвратом фактически пройденной дистанции и угла поворота. В магистерской это закрывает остаточный sim-to-real шум на стороне моторов и одновременно служит примером, что плагинная архитектура робота поддерживает разные уровни сенсорики и обратной связи.
-
Документирование архитектуры платформы. В магистерскую переходит описание того, что я уже построил за три спринта: контракты данных (наблюдения / действия / метрики), архитектура расширяемости (плагины треков, плагины роботов, плагины сценариев), инструменты воспроизводимости (model registry, metadata, calibration), интеграционные точки (Python обвязка, ONNX, REST API). Это центральная глава магистерской — про саму платформу, а не про конкретный ML-результат.
-
Демонстрационный режим и формальная eval для защиты. Полный заезд под запись с тремя ракурсами (внешний, бортовая камера, WebUI live-overlay) — материал для защиты магистерской.